In an earlier series of articles ending with
Multi-Core Ant Colony Optimization for TSP in Erlang I evaluated the performance of the Standard ML, Haskell, and Erlang
functional programming languages using a test problem of solving the traveling salesman problem using ant colony optimization. At the time I only had available a dual-core machine. I have re-run the tests using an Intel quad-core machine and the latest language versions available for Debian Linux.
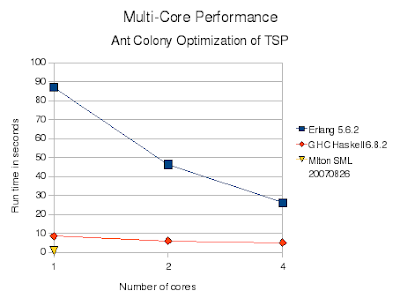
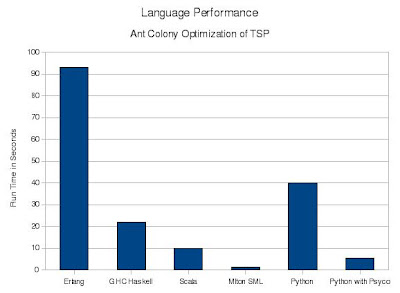
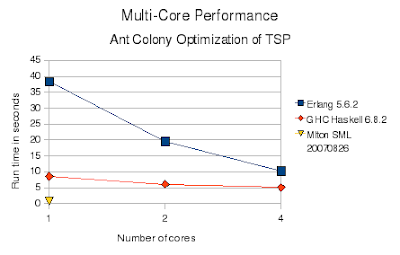
The results match my previous summary: Erlang is much slower than the others. Erlang is a bytecode interpreted virtual machine while the others are native code compilers. Erlang is also dynamically typed while the others are statically typed. Like Haskell, Erlang has immutable (single assignment) variables which force lots of copying. Unlike Standard ML and Haskell, no array type is provided so I had to inefficiently implement them using dictionaries. In Erlang each process (thread) does have a separate heap, so there is little interference between processes due to memory allocation or garbage collection. Near perfect speedup is achieved.
The CPU utilization graph (Erlang, then Haskell, then Standard ML) does show the lack of interference between Erlang threads which makes its speedup possible. Haskell achieves little speedup at higher numbers of cores.
Update: thanks, responses to comments:
As discussed at the end of an
earlier posting, based on email feedback I did try HiPE compilation with Erlang 5.5 on AMD. It provided no significant improvement, and was not compatible with multi-core operation. This time I again tried HiPE compilation with Erlang 5.6.2, and get the following with
erl:
$erl
Erlang (BEAM) emulator version 5.6.2 [source] [smp:4]
[async-threads:0] [kernel-poll:false]
Eshell V5.6.2 (abort with ^G)
1> c(ant,[native]).
./ant.erl:none: Warning: this system is not configured for
native-code compilation.
{ok,ant}
2>
Same for
erlc:
$erlc +native ant.erl
./ant.erl:none: Warning: this system is not configured for
native-code compilation.
So it appears the latest i386 Erlang available from Debian Linux apt-get doesn't support native compilation, probably because they chose to enable SMP support instead.
Erlang arrays are new in the latest release. Thanks for the info, I'll try them out.
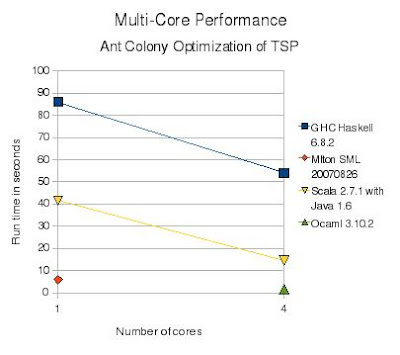
Yes, MLton SML with one core was the fastest. Older (pre-quad-core) versions of the code are available linked from the various ACO TSP pages and here:
Standard ML,
Haskell,
Erlang.
Actually the next language I will probably try is
Scala. Based on the Java JVM, it may inherit JIT native compilation and good SMP thread support. It also supports an Actor concurrency model like Erlang. Apparently Caml dialects don't support SMP. Of course for many problems (like ACO TSP :-) you are better off simply starting N different fast single-threaded instances of the program and collecting the results in Ruby or some-such. I am really looking for instances where using a SMP-capable language is a clear win over single-threaded C++. I haven't written a single-threaded STL C++ version of ACO TSP; I expect it could easily crush Mlton SML once you finally got the bugs out...
Here are the raw numbers, in seconds:
Cores Erlang Haskell SML
1 87.0 8.6 0.76
2 46.3 6.1
3 34.6 5.5
4 26.2 5.1
When I increase the iterations in Haskell by 5x the runtime goes up by 5x (43 secs with 1 core, 26 secs with 4 cores), still showing the same pattern of decreasing improvement with increased cores.
Update 2: see
new post for revised Erlang code and results.
Update 3:Turns out Erlang HiPE is available in Debian as a separate package (erlang-base-hipe), and is now SMP compatible. But the improvement is only 5%, or 11% if you also native compile dict.erl.