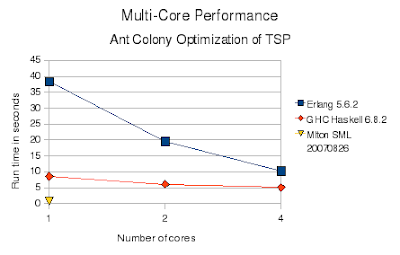
Cores Erlang Haskell SML
1 38.4 8.6 0.76
2 19.6 6.1
3 14.5 5.5
4 10.3 5.1
Here is the revised Erlang source code, as well as the Haskell quad-core source code used in tests. The MLton Standard ML implementation is still single-core, as MLton does not have SMP support (see comments below).
Update: Added new post with Scala implementation.
11 comments:
I'm curious as to why you didn't run ML at the higher number of cores with the other benchmarks? Simply because it was that much faster in the initial test, thus not meriting further examination?
MLton SML doesn't have SMP support. The included Concurrent ML library implements user-level threads inside a single OS thread.
MLton SML does have Posix.Process.fork and exec, so it could be done the hard way (as was suggested for JoCaml in a comment on the earlier posting). Most languages support this (such as Ruby's Kernel.fork and exec); I am more interested in testing languages with higher level abstractions such as Erlang Actors or Haskell Parallel Strategies.
A recent selling point for functional languages has been that they will make utilizing multi-core CPUs easier. Fork+exec is not easier, and doesn't (easily) allow shared memory or message passing.
In earlier articles I have tested language facilities for spreading processes across multiple machines, such as Distributed Ruby (DRb) and Alice SML Remote Futures. These could of course be targeted to multiple cores of the same machine.
BTW, the presented SML run time number is actually the serial run time for a single seed value, multiplied by 4 (to match the work done by the other implementations). With fork/exec or a Ruby dispatcher program the run time would drop to 1/4 on 4 cores.
That brings up an interesting point: I wonder how hard it would be to implement an actor library in ML. Obviously the language is fairly limited, especially relating to separate compilation. Still, it would be interesting to see...
I took the liberty of rewriting (cleaning up) and optimizing the SML version of the program. My version is roughly twice as fast as the original and is written in a more traditional SML style mostly avoiding the use of mutable ref-cells and while-loops. Performance can further be slightly improved by compiling without array bounds and integer overflow checking. You can find my version here.
My version jumps through some hoops to produce the exact same results as the original program (although the output is formatted slightly differently). I'll probably ditch that level of compatibility in the future and simplify the program further.
I promise to make a parallel version using shared memory IPC if you can get either the parallel Erlang or the parallel Haskell version within 10% of the serial SML without using ugly unsafe low level optimizations (e.g. using the FFI in Haskell).
It looks like Erlang (despite being slower overall), scales better as the number of cores goes up.
Speedup values: (1 core is 1X)
Cores Ideal Erlang Haskell
1 1.00 1.00 1.00
2 2.00 1.96 1.41
3 3.00 2.63 1.56
4 4.00 3.70 1.69
6* 6.00 5.22* 2.52*
8* 8.00 6.96* 3.36*
12* 12.00 10.44* 5.04*
16* 16.00 13.92* 6.72*
32* 32.00 27.84* 13.44*
64* 64.00 55.68* 26.88*
128* 128.00 111.36* 53.76*
*extrapolated
In this sample Erlang scales worst at 3 cores. Ideally it should be 3X speedup, while it is actually 2.63X speedup. Assume that Erlang scales at this worst observed rate (ie. 87% per added core). In the sample Haskell scales at best 71% per core and at worst 42% and appears to scale exponentially less well as more cores are added. Assume that Haskell scales at 42% per core.
Erlang scaling extrapolation formula:
[X*0.87 || X <- [6, 8, 12, 16, 32, 64, 128]]
Extrapolating (naively) to a 128 core machine shows Haskell in the lead. This assumes that Haskell continues to scale at the linear rate it did from 3 to 4 cores. Haskell may actually be far less competitive since it appears to get exponentially less speedup from each added core.
My intuition from the trend of the sample execution times is that Erlang would pull out in the end. I am far too tired to figure out the decay series for Haskell's speedup so I got lazy and did a linear speedup comparison. Someone less tired and addled should correct my faulty analysis :D
Extrapolation formula for Erlang (assume linear 87% speedup per core):
[38.4/Y || Y <- [X*0.87 || X <- [6, 8, 12, 16, 32, 64, 128]]].
Extrapolation formula for Haskell (assume linear 42% speedup per core, bad assumption):
[8.6/Y || Y <- [X*0.42 || X <- [6, 8, 12, 16, 32, 64, 128]]].
* X*0.42 should REALLY be replaced with an exponential decay function f(X)
Execution time:
Cores Erlang Haskell
1 38.4 8.6
2 19.6 6.1
3 14.5 5.5
4 10.3 5.1
6* 7.4* 3.4*
8* 5.5* 2.6*
12* 3.7* 1.7*
16* 2.8* 1.3*
32* 1.4* 0.6*
64* 0.7* 0.3*
128* 0.3* 0.2*
*extrapolated
I suspect that a real test would yield values closer to those below.
Execution time:
Cores Erlang Haskell
1 38.4 8.6
2 19.6 6.1
3 14.5 5.5
4 10.3 5.1
6* 7.4* 4.7^
8* 5.5* 4.3^
12* 3.7* 3.9^
16* 2.8* 3.5^
32* 1.4* 3.1^
64* 0.7* 2.7^
128* 0.3* 2.3^
*extrapolated
^intuition
Thanks for the interesting benchmark!
I get similar results for Haskell but my results for MLton (in 64-bit) are 2x faster than yours. I wrote a simple parallel OCaml implementation that is not only several times faster than all of your implementations but also much smaller at only 131 lines of code.
For 1000 iterations I get 0.49s for my parallel OCaml, 2.9s for your SML and 52s for your Haskell on my dual core 4400+ Athlon64. So OCaml is over 100x faster than Haskell and shorter as well.
Incidentally, I think Alain's extrapolations are absurd. You can't take results from 4 cores and extrapolate to compare at 128 cores. Not only would the errors be huge (had he quantified them) but his model is inaccurate anyway. Current research shows Haskell's performance being *degraded* moving beyond 4 cores and Alain's model cannot reproduce that.
Finally, your notion that functional languages are well placed for parallel computing is interesting but it can only bear out in practice for functional languages with concurrent garbage collectors and that currently means F#. However, your parallel implementation of this benchmark is embarrassingly parallel and the lack of fine-grained parallelism (which is ubiquitous in real programs) makes the parallel results rather uninteresting. You should define the random number generator and, therefore, the exact results generated by the program and then require that parallel implementations generate identical output to the serial implementations. Only then will you have a decent test of parallelism.
Flying Frog;
No big disagreements. Yes, my results are for 32-bit Linux.
A common random number generator would also make testing much easier. Right now each implementation produces different results in serial mode. And the nature of the program (iterative optimization) makes verifying correctness difficult. Earlier cross-platform benchmarks I did with a ray tracer were much easier to verify: does the rendered picture look the same? I did double-check that none of the re-implementations didn't have an extra "inner loop" slowing it down, and my results on the serial relative performance between languages do match those presented at the Computer Language Shootout. They also match intuition: bytecode interpreted versus native compiled, static versus dynamically typed (yes, I've read Steve Yegge's post on the potential for improvement :-) . I don't have as much intuition yet around the performance potentials of lazy versus strict and side-effect-free versus not.
For actual performance testing I expect people will insist on their native random generator. Note the earlier poster Vesa, one of the MLton SML developers, actually moved the published random number generator algorithm I used into the language libraries. Cross language also imposes peculiar limitations -- the first language I implemented ACO TSP in, Alice SML, has 31-bit integers.
Serial and parallel implementations should already produce identical results, since each version creates a separate closure-style random number generator per thread or seed value used. Having threads contend for the same generator would be non deterministic and unfair.
As acknowledged earlier this test is embarrassingly parallel. In some ways that is a good thing: the CPU traces clearly point out the memory allocation and garbage collection differences between Erlang and Haskell. And none of this started out as a test. Initially I wanted to learn a functional language (Alice SML). And try out the distributed features (remote futures) on a few machines. Then I wanted to try out some different functional languages (Haskell, Erlang), so I re-wrote the program I already had. Performance wasn't always the goal; I was trying out different language features and learning as I went. But so far other posters tuning results leave the relative comparisons (single core MLton SML >much faster than> multi-core Haskell >much faster than> multi-core Erlang) unchanged.
Fair enough. I've posted my parallel OCaml implementation on comp.lang.functional. I think you'll agree it is much clearer and much faster than all other implementations. :-)
BTW, just found more (mostly old) comments on reddit.
posted new implementation in Scala.
Post a Comment