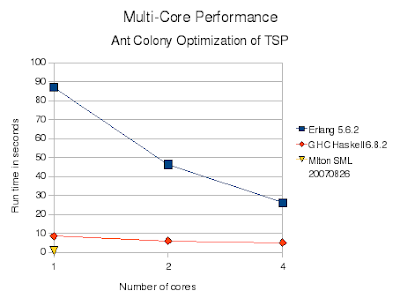
The results match my previous summary: Erlang is much slower than the others. Erlang is a bytecode interpreted virtual machine while the others are native code compilers. Erlang is also dynamically typed while the others are statically typed. Like Haskell, Erlang has immutable (single assignment) variables which force lots of copying. Unlike Standard ML and Haskell, no array type is provided so I had to inefficiently implement them using dictionaries. In Erlang each process (thread) does have a separate heap, so there is little interference between processes due to memory allocation or garbage collection. Near perfect speedup is achieved.
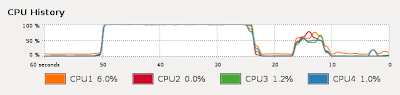
The CPU utilization graph (Erlang, then Haskell, then Standard ML) does show the lack of interference between Erlang threads which makes its speedup possible. Haskell achieves little speedup at higher numbers of cores.
Update: thanks, responses to comments:
As discussed at the end of an earlier posting, based on email feedback I did try HiPE compilation with Erlang 5.5 on AMD. It provided no significant improvement, and was not compatible with multi-core operation. This time I again tried HiPE compilation with Erlang 5.6.2, and get the following with erl:
$erl
Erlang (BEAM) emulator version 5.6.2 [source] [smp:4]
[async-threads:0] [kernel-poll:false]
Eshell V5.6.2 (abort with ^G)
1> c(ant,[native]).
./ant.erl:none: Warning: this system is not configured for
native-code compilation.
{ok,ant}
2>
Same for erlc:
$erlc +native ant.erl
./ant.erl:none: Warning: this system is not configured for
native-code compilation.
So it appears the latest i386 Erlang available from Debian Linux apt-get doesn't support native compilation, probably because they chose to enable SMP support instead.
Erlang arrays are new in the latest release. Thanks for the info, I'll try them out.
Yes, MLton SML with one core was the fastest. Older (pre-quad-core) versions of the code are available linked from the various ACO TSP pages and here: Standard ML, Haskell, Erlang.
Actually the next language I will probably try is Scala. Based on the Java JVM, it may inherit JIT native compilation and good SMP thread support. It also supports an Actor concurrency model like Erlang. Apparently Caml dialects don't support SMP. Of course for many problems (like ACO TSP :-) you are better off simply starting N different fast single-threaded instances of the program and collecting the results in Ruby or some-such. I am really looking for instances where using a SMP-capable language is a clear win over single-threaded C++. I haven't written a single-threaded STL C++ version of ACO TSP; I expect it could easily crush Mlton SML once you finally got the bugs out...
Here are the raw numbers, in seconds:
Cores Erlang Haskell SML
1 87.0 8.6 0.76
2 46.3 6.1
3 34.6 5.5
4 26.2 5.1
When I increase the iterations in Haskell by 5x the runtime goes up by 5x (43 secs with 1 core, 26 secs with 4 cores), still showing the same pattern of decreasing improvement with increased cores.
Update 2: see new post for revised Erlang code and results.
Update 3:
Turns out Erlang HiPE is available in Debian as a separate package (erlang-base-hipe), and is now SMP compatible. But the improvement is only 5%, or 11% if you also native compile dict.erl.
10 comments:
Erlang is a bytecode interpreted virtual machine
Did you try compiling erlang code with HiPE? You'll most probably get a big speed difference.
Unlike Standard ML and Haskell, no array type is provided
Did you try latest version of erlang, which does support arrays?
http://www.erlang.org/doc/man/array.html
> You'll most probably get a big speed difference.
For some definition of big.
So basically, SML was the fastest by far even though it only used 1 core, correct?
Is the source code for the ML version available?
Also, what about trying JoCaml which is an OCaml dialect which supports the Join Calculus concurrency model?
looking at your graph it looks like haskell had big performance gain, at least 50% but your test is so small that it does not show in your graph. make problem where haskell spends 90 sec in one core and see how it looks like.
Thanks all for the feedback. Responses in Update section, above.
So I noticed that in the Haskell code, you hardwired in your parallelism to only create two threads at a time, regardless. Naturally, therefore, there's not going to be a great deal of scaling past two cores. Did you update the code to use a different concurrency model since then?
With concurrent code, you generally get something more erlang-like where you divvy up the problem to a number of worker threads. With parallel code, you want to figure out a useful unit of work to "spark" and then go wild sparking lots at once, rather than trying to manually tie your sparks to the amount of processors.
For the quad-core test the Haskell code was revised to run 4-way parallel:
paths = parMap rwhnf f [1,2,3,4]
(path1, path2, path3, path4) =
(paths !! 0, paths !! 1, paths !! 2,
paths !! 3)
len1 = pathLength cities path1
len2 = pathLength cities path2
len3 = pathLength cities path3
len4 = pathLength cities path4
The Erlang code was also modified:
spawn(ant,parallelWork,[Seed,1,Boost,
Iter,NumCities,self()]),
spawn(ant,parallelWork,[Seed,2,Boost,
Iter,NumCities,self()]),
spawn(ant,parallelWork,[Seed,3,Boost,
Iter,NumCities,self()]),
spawn(ant,parallelWork,[Seed,4,Boost,
Iter,NumCities,self()]),
Both collect and compare the 4-way results appropriately.
Apparently Caml dialects don't support SMP.
JoCaml? However, I think that you might actually need to fork within the spawns - check out this blog entry on the JoCaml entry to Tim Bray's WideFinder contest: http://eigenclass.org/hiki/fast-widefinder
Taking a look at his fastest JoCaml multi-core implementation it looks like he had to do:
let master filename =
let register, wait = wide_finder filename in
Join.Ns.register Join.Ns.here "register" register;
Join.Site.listen addr;
for i = 1 to num_workers do
match Unix.fork() with
| 0 -> Unix.execv exec_name [| exec_name; "--client" |]
| _ -> ()
done;
wait()
Even so, he seems to have acheived the best performance as compared to other engries (lots of Erlang entries).
Just modifying the Erlang code to use the mapping and updating functions in dict in the following 2 functions:
updatePher(Pher, Path, Boost) ->
WPath = wrappedPath(Path),
Pairs = lists:zip(Path, WPath),
F = fun(Key,M) ->
dict:update_counter(Key, Boost, M)
end,
lists:foldl(F, Pher, Pairs).
evaporatePher(Pher,MaxIter, Boost) ->
Decr = Boost / MaxIter,
F = fun (_, Val) ->
if Val >= Decr -> Val - Decr;
true -> 0.0
end
end,
dict:map(F, Pher).
gives a speed up by a factor 2 in the sequential main and a factor 3.3 in the parallel main. This on a dual core machine.
See new post for revised Erlang code and results.
Post a Comment